
reading notes of a survey about knob tuning
Everything
tuning problems
- what are the tuning objectives
- performance evaluation
- configure the databases for high performance => throughput, latency
- improve resource utilization , thus reduce maintenance costs without sacrificing performance => i/o, memory usage
- a tuning methoad is evaluated from
- performance => how well it can achieves the objectives in a given scenario
- Overhead => how much time or system resource it requires
- Adaptivity (more crucial for online tuning) => how well it achieves the objectives in new scenarios
- safety (more crucial for online tuning) => whether it can avoid selecting knob settings that cause performance degradation
- performance evaluation
- what to tune
- how to evaluate the knob-performance relations
- how to select important knobs
- With what to tune => how to select tuning features (workloads, database state, hardware enviroments), which can reflect the database execution behaviors and potentially affect the tuning performance
- tuning fatures are in high demensional space
- many features capture similar tuning characteristics => drop the redundant features
- many fatures are in deversified domains => combine or embed useful features into the same input domain
- tuning fatures are in high demensional space
- how to tune
- the search space is large
- obtaining the tuning performance is costly
- Not intelligently recommend knob setting based on scenario characteristic and tuning objectives
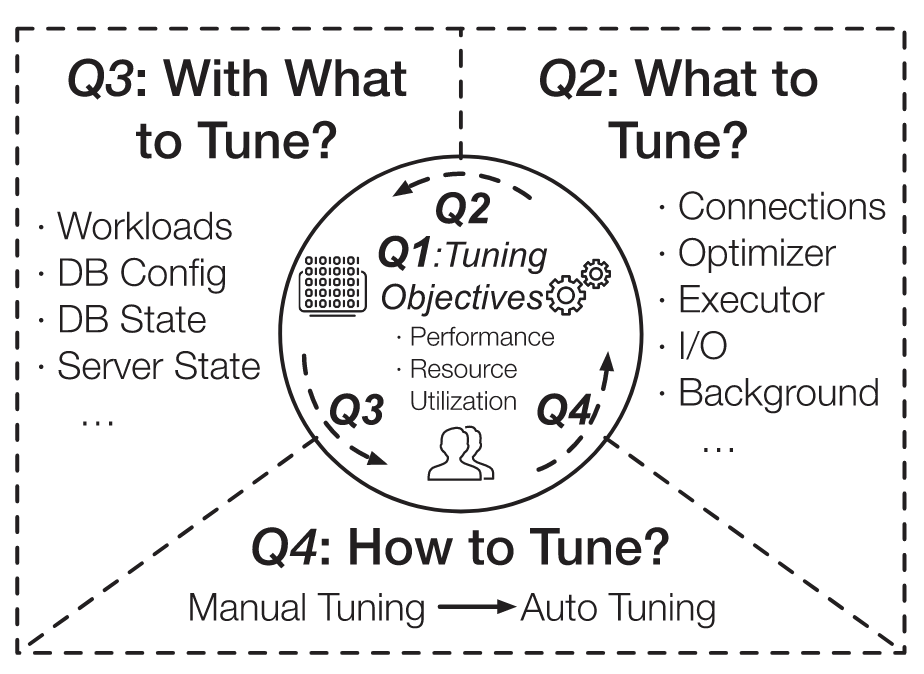
framework
knob tuning includes
knob selection
Main categories of knobs
- access control
- affect the database performance by balancing the cocurrency and execution efficiency
- vital to select cocurrency knob to balance throuput and latency
- query optimization
- controls the generation of query plans
- whether to use sequential scan or index scan
- affect the quality of generated query plans from three main aspects
- physical operators
- planning policies
- cost evaluation
- can generate efficient query plans that significantly improve the query performance.
- controls the generation of query plans
- quey execution
- aim to configure physical execution mechanisms
- Background processes => BP
- resource management => RM
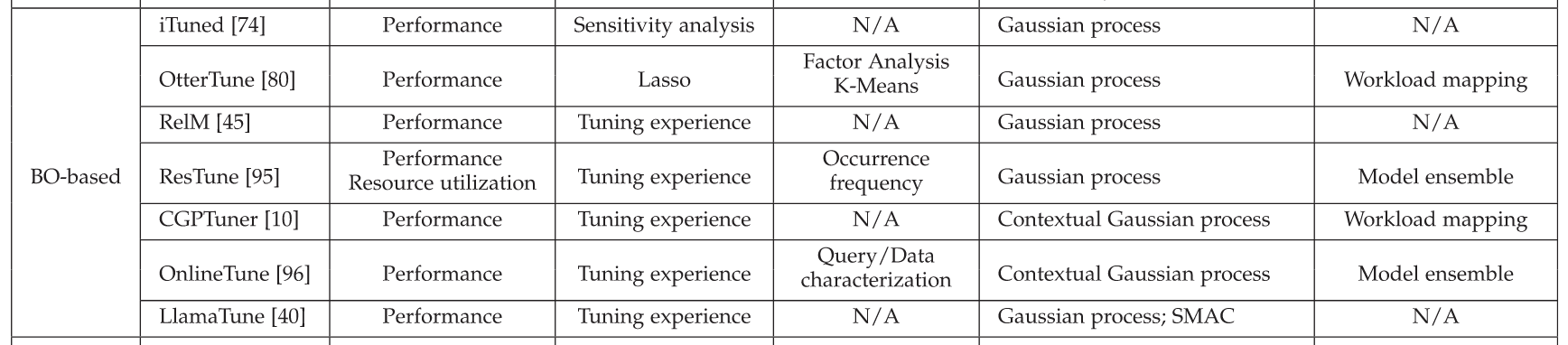
Existing selection algorithm
=> filter unimportant knobs and reduce the configuration space
Empirical-based
Ranking-based
sample collection => aim to provide high-quality samples (knob settings) for knob ranking
- randomly select knob settings as samples => lead to bias and miss many conbinations of effective knob values
- latin hypercube sampling (LHS) => cannot utilize prior knowledge to filter inferior knob settings, which lead to many ineffective samples
- hybrid method used in HUNTER => generate samples based on both the empirical rules and search algorithm, hard to generalize to different scenarios
knob ranking => aims to rank the knobs based on collected configuration samples
Plackett & Burman (P&B)
a linear regression method called Lasso used in OtterTune
=> takes samples as independent variables (X) and takes the selected performance metrics as dependent variables (y).
=> It employs a regularized version of least squares to rank the knobs and it’s a regression model function that shrinks the weights of the knobs towards those with high-performance impact. By automatically adjusting the value of parameter lambda, Lasso can control the number of knobs it selects.
=> however it ignores the non-linear relationship between knobs so that the selected knob affects the ordering of the other knobs
ensemble of regression trees
=> builds a random forest for the samples and the corresponding performance and selects important knobs based on the random forests.
=> it can capture the non-linear relationship between knobs
pros of above two
- rely on simple assumptions
- can’t capture the correlations of knobs
- miss valuable knobs
- rely on a large numer of samples
Feature selection
commonly-used features
tuning features includes:
workload features
- capture the workload characteristic
- operators, execution costs
- three main characteristic that determine the tuning requirements of different workloads
- query featrues
- concurrency features
- accessed data features
database metric features
- capture the underlying database characteristic
- extracted from executions
- can infer the database state under the workload
- three categories to reflect the execution state:
- tuning objective metrics => 1) identify important knobs, 2) evaluate tuning methods and 3) reflect the database performance or resource usage
- latency
- throughput
- database runtime metrics => utilize database state metrics to reflect the workloads at database level and query state metrics for query-level tuning
- database state metrics
- query state metrics
- table statistics => 1) reflect the data distribution and 2) profile the scale of access data
- tuning objective metrics => 1) identify important knobs, 2) evaluate tuning methods and 3) reflect the database performance or resource usage
existing techniques
two main approaches
workload encoding
the read/write ratios of the workload
=> the read-only, write-only, and read-write workloads.
extracting detailed query information to represent the workload execution features
=> build a vector based on the query plan and the cost estimation
=> the vector contains three parts, i.t., the query types, the tables used by the query, and the query cost
occurency frequency
=> only usilize the sql query features
- selectively extract some keywords for queries that frequently appear and utilize a probabilistic model called Term Frequency - Inverse Document Frequency (TF-IDF), which helps to identify the importance of extracted keywords
- infer the cost levels by utilizing random forest to classify queries based on their TF-IDF feature vectors.
- utilize the TF-IDF feature vectors and average cost levels to represent the corresponding workload
database metric selection
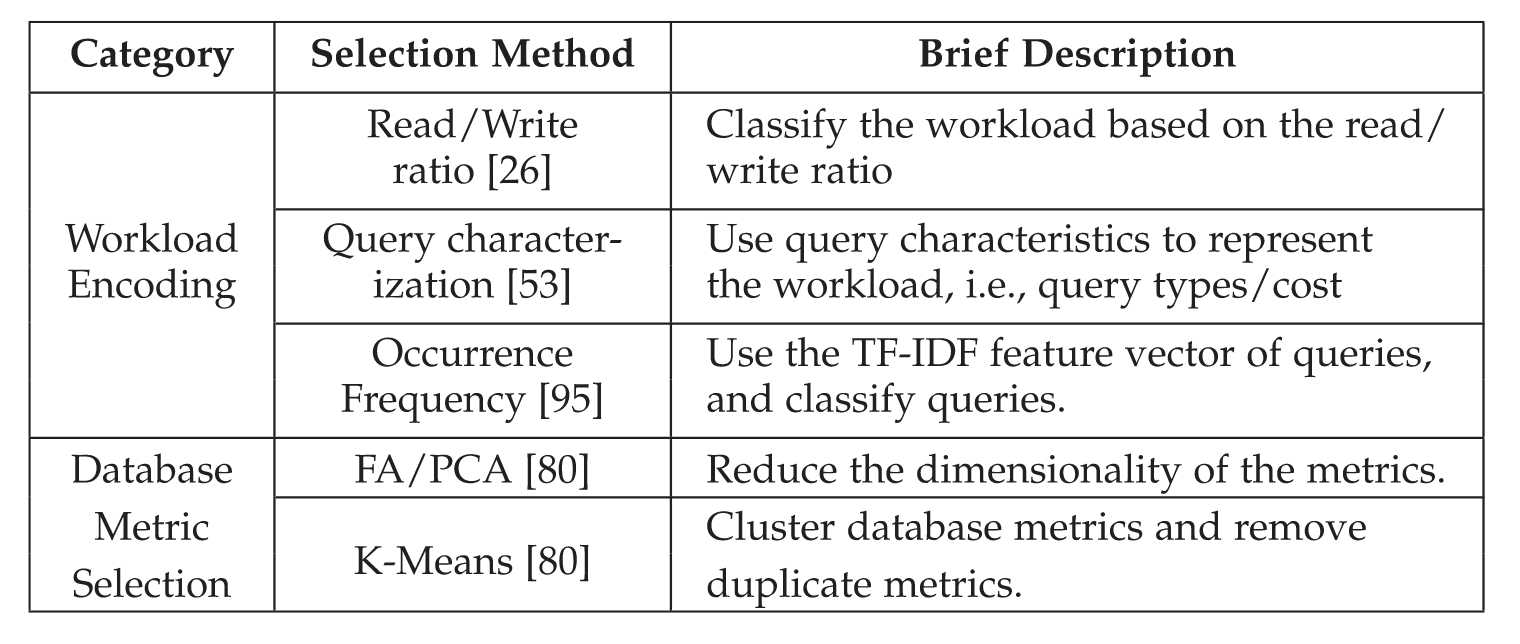
there are hundreds of metrics, most of which may not effectively represent the database state and cause a great tuning burden.
thus metric selection methods aim to reduce the metrics to a smaller set based on the correlation. metric selection methods include two main steps:
- dimensionality reduction techniques tp reduce the deminsionality of metrics, e.g., factor analysis (FA) or Principal component analysis (PCA), used in ottertune and hunter accordingly
- for the processed metrics, some metrics have similar functionality for knob tuning
Tuning methods
formalize the knob tuning problem into an optimization problem, which given a workload and a suite of adjustable knobs, select the optimal knob settings under predefined objectives and constraints
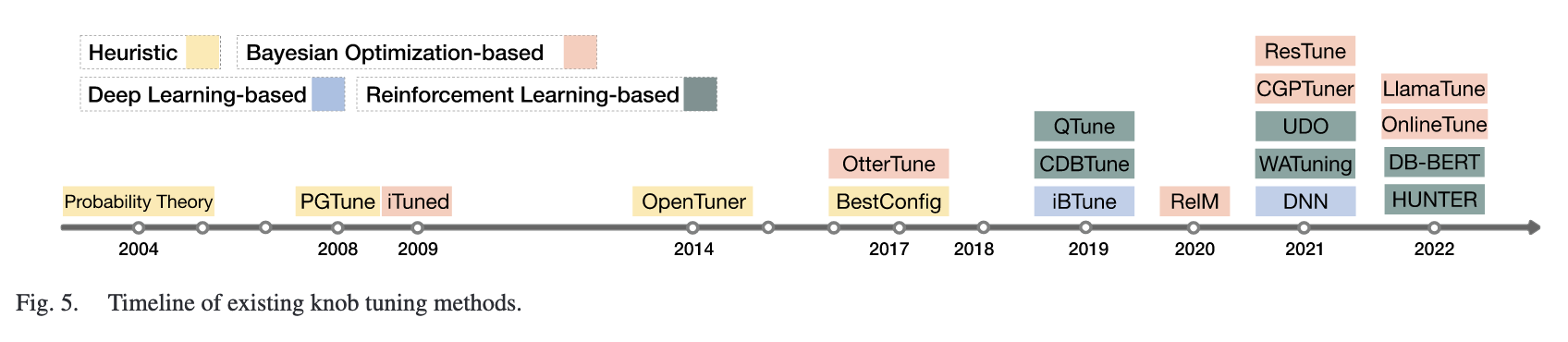
4 tuning methods
heuristic
rule-based method
PGTune
search-based method
- an ensemble method combining multiple search methods
- OpenTuner
- a sampling-optimization method
- BestConfig
cons and pros
- cons => easy to implement
- pros
- randomly sample, challenging to find promising settings among large configuration space within limited tuning time
- can not use historical tuning data and prior knowledge
- waste time in evaluating the search space of inferior settings
bo-based
key modules
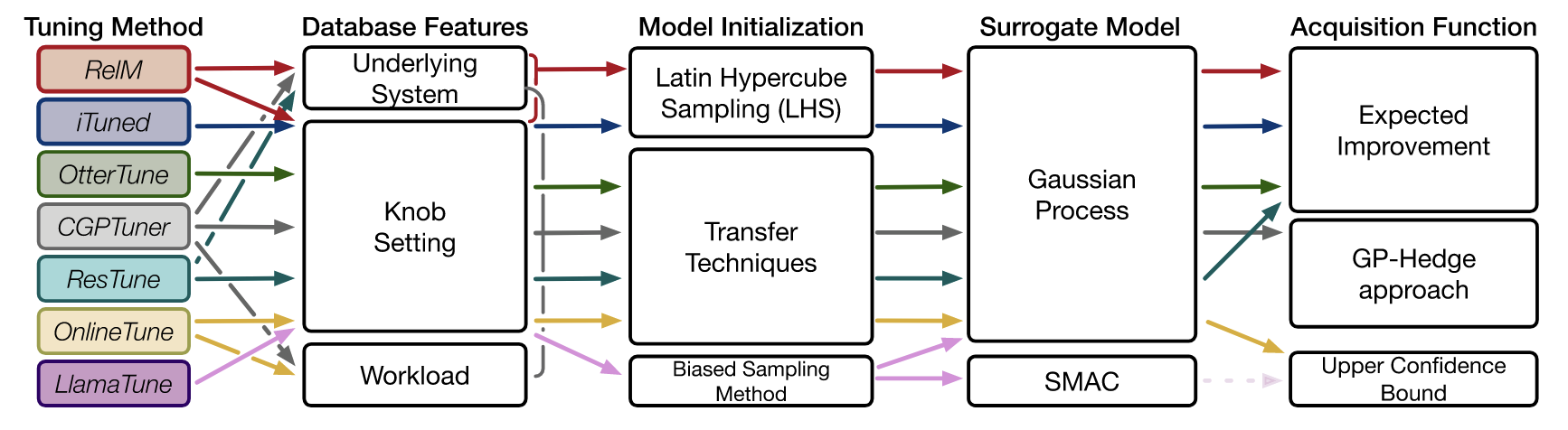
surrogate model
- it maps the relationship between knob settings and database performance
acquisition function
model initialization
- initialize the tuning model with some knob setting samples
- not only affect the convergence speed but also the selected knob setting quality
data features
Involves knob settings and possibly other database metrics and the surrogate model uses the data features to approximate the knob-performance relationship
Include:
- knob setting samples => involve the selected knobs and their values (of course with their performance)
- Workload/ runtime featuresc => capture the features of changing workloads
- underlying system features
cons and pros
- cons
- can quickly find high-quality knob settings when the knob number is small
- do not require prepared training data
- pros => cannot efficiently represent and explore large configuration space since it base on probability distribution assuming thhe knob-performance relations following gaussian distribution
deep learning
=> replace the gaussian process model with neural networks
- pros => require a large number of high-quality samples to train
reinforcement learning
=> proposed to explore suitable settings by the inteaction between the agent (the tuning model) and the environment (the taeget database)
- Cons
- do not require prepared training data
- have no limitation on the size of the configuration space
- pros
- the overhead is much higher than bo-based method
- performance greatly depends on the initially sampled knob settings
challenges summary
=> How existing methods address those challenges
transfer techniques
=> utilize historically well-trained tuning models
three transfer teckniques have been proposed in knob tuning
- workload mapping
- learned workload embedding
- model ensemble
common feature extraction
directly extracts the common features of different workloads
two main challenges
workload may have different access patterns, hard to embed for unseen workloads
need to design an extra workload embedding model, which require much prepared training data
adaptive weight transferring
- adapt to new scenarios by preparing a suite of tuning models that are welltrained under historical workloads
- use similarity to map new workload to an old one
knob tuning system
- commercial relational database
- big data analytics systems
research challenges and future opportunities