如题
Greenplum数据库xlog文件清理
问题:跑实验跑到一半报磁盘空间不足,前面跑的那次迭代到100次的时候都没有出现磁盘空间不足的情况,但是新的一次迭代几次就出现了这种情况。因此初步怀疑是之前跑的实验留下来的日志等文件没有被释放掉,占了很大的空间。
一开始的想法是找到那些文件夹(在配置文件里DATA_DIRECTORY设置的文件夹下)并删掉.
1 2 3 4 5 6 7 df -hdu -h --max-depth=1 | sort -hr
找着找着发现每个节点的内部的base和xlog占用了好几个G,反而是一开始怀疑的pg_log文件夹没多大,所以开始琢磨怎么清理xlog里面的东西。xlog下面是一堆以十六进制编码命名的文件,这些文件是数据库的事务日志(WAL)文件。在Greenplum中,这些文件记录了数据库的所有修改操作,以保证数据库的持久性和一致性。直接删肯定是会出问题的。
操作如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 gpstop cd ./greenplum/primary/gpsne1pg_controldata ./ | grep -E "Latest checkpoint's NextXID|Latest checkpoint's NextOID" > Latest checkpoint's NextXID: 0/4837 Latest checkpoint' s NextOID: 196775pg_resetxlog -o 196775 -x 4837 -f ./ > WARNING: Do not use this on Greenplum. pg_resetxlog might cause data loss and render system irrecoverable. Do you wish to proceed? [yes /no] yes Transaction log reset
最后应该是清理了5G这样,继续跑实验其实还是会出现磁盘空间不够(差一点卡临界值),搞了半天顿悟到:把所有节点和配置文件删掉重新gpinit效果也是一样的。
被搞烦了(暴躁),与其交给运气不如remake一把。
根文件系统扩容
上面提到,挂载在”"下的/dev/nvme0n1p1的空间大小只有16G,非常痛苦,根本不够用,现在来进行一个彻底的解决。
先看一下初始情况
1 2 3 4 5 6 7 8 9 10 11 df -h> Filesystem Size Used Avail Use% Mounted on udev 63G 0 63G 0% /dev tmpfs 13G 2.1M 13G 1% /run /dev/nvme0n1p1 16G 13G 2.0G 87% / tmpfs 63G 56K 63G 1% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 63G 0 63G 0% /sys/fs/cgroup ops.utah.cloudlab.us:/share 19T 15G 19T 1% /share ops.utah.cloudlab.us:/proj/risb-PG0 100G 256K 100G 1% /proj/risb-PG0 tmpfs 13G 0 13G 0% /run/user/20001
给分区扩容时会用到一个工具parted,先进行安装;删除和新建分区用fdisk就行;
1 2 sudo apt-get updatesudo apt-get install parted
使用lsblk或者fdisk命令查看当前的分区情况,确认要调整的目标分区
1 2 3 4 5 6 7 8 9 10 lsblk > NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 259:1 0 1.5T 0 disk ├─nvme0n1p1 259:4 0 16G 0 part / ├─nvme0n1p2 259:5 0 3G 0 part ├─nvme0n1p3 259:6 0 3G 0 part [SWAP] └─nvme0n1p4 259:7 0 1.4T 0 part nvme1n1 259:3 0 1.5T 0 disk
根据上述输出,可得到如下信息:
nvme0n1p1:分区大小为16GB,挂载在/目录,根分区,即操作系统所在的分区。
nvme0n1p2:分区大小为3GB,类型为part,可能是一个其他用途的分区。
nvme0n1p3:分区大小为3GB,类型为part,是交换空间(SWAP)分区,用于交换数据和内存管理。
nvme0n1p4:分区大小为1.4TB,类型为part,可能是另一个用途的分区。
nvme1n1硬盘没有分区信息,它是一个1.5TB大小的未分区硬盘。
现在要做的事情是 ① 把nvme0n1硬盘里2到4号的分区删掉;② 把空间几乎全挪给1号;③ 最后再腾出一小段空间重新分配一个分区,再将其设置为交换区。注意原先的3号由于是交换区,删掉前要先将其禁用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 sudo swapoff /dev/nvme0n1p3sudo fdisk /dev/nvme0n1(d删除) | n新建 | w保存 | print 查看各区情况 | q退出 sudo parted /dev/nvme0n1resizepart 1 +1200G sudo fdisk /dev/nvme0n1d删除 | (n新建) | w保存 | print 查看各区情况 | q退出
假设resize完nvme0n1p1后,新建的待设置为交换区的分区为nvme0n1p2,执行下列操作,将nvme0n1p2 设置为交换区
1 2 3 sudo mkswap /dev/nvme0n1p2sudo swapon /dev/nvme0n1p2
上述操作结束后还要对/etc/fstab进行调整,该文件记录了系统引导时需要挂载的分区信息,调整该文件以确保系统可以正确地挂载分区。
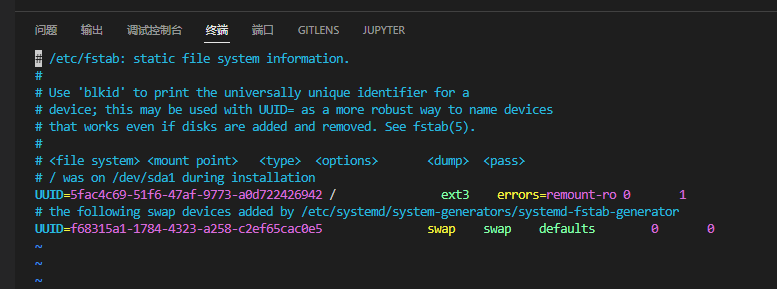
1 2 3 4 5 6 sudo blkid> /dev/nvme0n1p1: UUID="5fac4c69-51f6-47af-9773-a0d722426942" TYPE="ext3" PTTYPE="dos" PARTUUID="90909090-01" /dev/nvme0n1p2: UUID="d9fa5d04-4799-4b8a-affd-69cbd1a0c808" TYPE="swap" PARTUUID="90909090-02" /dev/nvme0n1: PTUUID="90909090" PTTYPE="dos" sudo vim /etc/fstab
修改对应的UUID号,下图中只需修改swap区的UUID号即可。将紫色第二行改为上述查询到的/dev/nvme0n1p2的UUID(d9fa5d04-4799-4b8a-affd-69cbd1a0c808)。
检查一下别填错了(慎重),保存退出后执行sudo reboot即可,可能需要等待一会才能重新连接服务器(连不上先别慌)
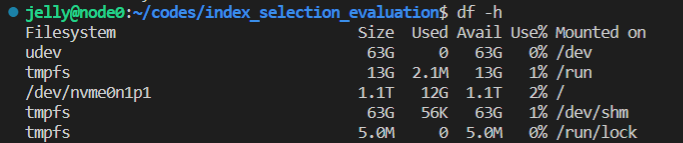
重新连上后执行如下命令来扩展文件系统以适应分区大小并重新查看一下结果
1 sudo resize2fs /dev/nvme0n1p1
无法适用psycofg2连接postgreSQL 参考 这篇帖子 ,报错如下
1 2 3 4 5 6 7 >> conn=psycopg2.connect(database="demo" , user="" , password="123" ,port=5432) Traceback (most recent call last): File "<stdin>" , line 1, in <module> psycopg2.OperationalError: could not connect to server: No such file or directory Is the server running locally and accepting connections on Unix domain socket "/var/run/postgresql/.s.PGSQL.5432" ?
执行如下命令,如果显示/var/run/postgresql/.s.PGSQL.5432已存在,先删掉
1 sudo ln -s /tmp/.s.PGSQL.5432 /var/run/postgresql/.s.PGSQL.5432
查看openbox的可视化结果 操作如下
1 2 cd /python3 -m http.server 7000
启动后找到对应.html文件即可