
使用GAN
Many supervised machine learning algorithms heavily rely on the availability of substantial annotated failed disk data which unfortunately exhibits an extreme data imbalance, resulting in suboptimal performance and even inability at the beginning of their deployment, i.e., cold starting problem.
model

1. data processing
① Feature Selection:
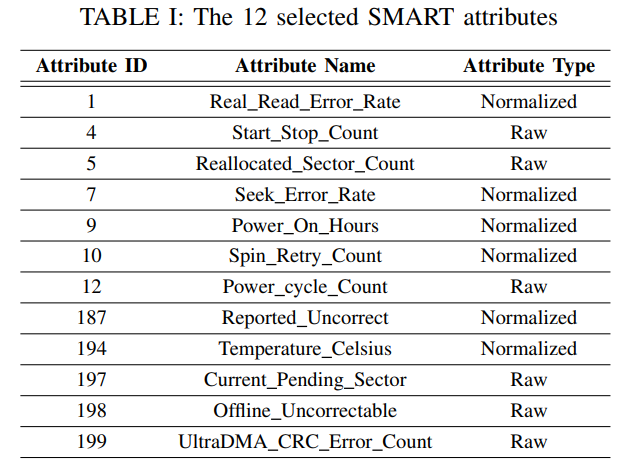
② Construction of 2D-SMART attributes:
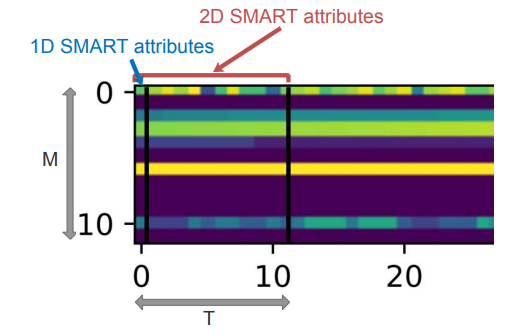
③ normalize
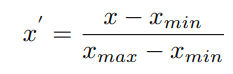
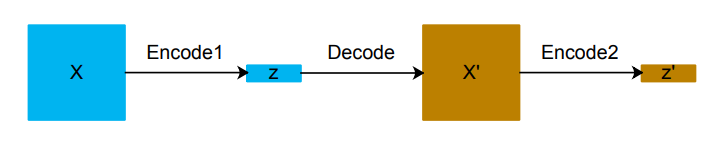
2. GAN-based method
① GAN-based anomaly detection
② fine-tuning technique to do model updating
- what:problem of model aging, the prior trained model will lose validity on the new coming SMART data
- how: transfer information from one dataset to another one.
- accumulation updating strategy: reuses the old and retrains it on new coming data
- other strategy: discards the old model and trains a brand-new model using new coming data
- challenging: sample labeling ⇒ automatic online labeling method proposed by Xiao.
- use first-in-first-out queue
- semi-supervised: only use healthy samples
- relaxes the updating frequency: use batches of samples ( constant time inrerval, dataset S, full, into 2D-SMART attributes chunks )
experiments
1. dataset
- from Backblaze, span a period of 12 months ranging from January 2017 to December 2017
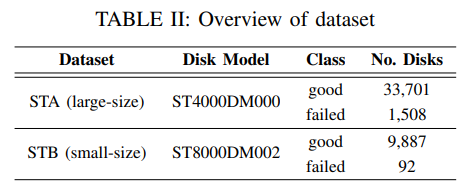
- divide disks in each dataset randomly into training set and test set in the proportion of 7:3
2. algorithms
- iterations: 1000, lr: 0.01, optimization: Adam
- RF ( state-of-the-art ): 150 trees
- SVM: LIBSVM ⇒ polynomial, sigmal, linear
- BP: 3 layers with 64 nodes in th ehidden layer and relu
- SPA ( size of z: 100, T: 12 which means the input shape of image-like representation )
- comparision
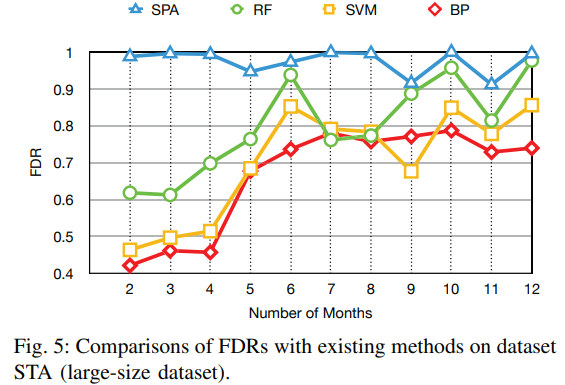
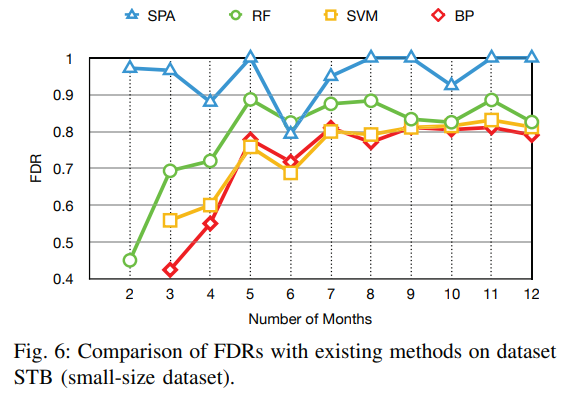
3. preponderance
① avoid the cold starting problem
- use 2D Image-Like Representation
- T = 12
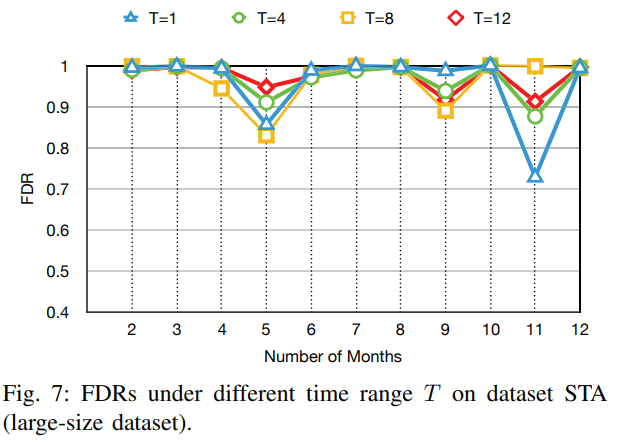
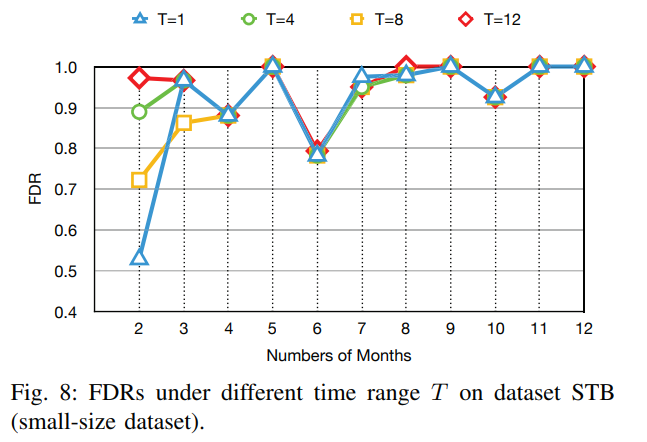
② alleviate model aging problem
- use fine-tuning
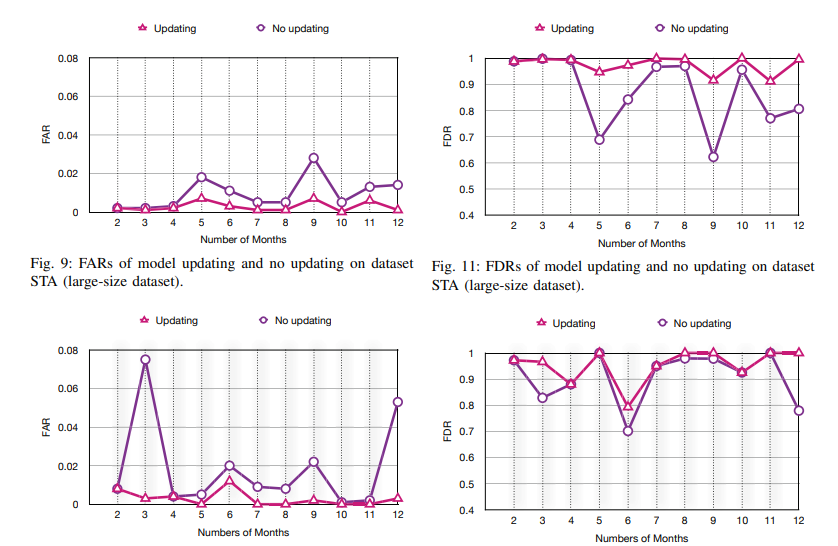
conclusion
Compared with the state-of-the-art supervised machine learning based methods, our approach predicts disk failures at a higher accuracy for the entire lifetime of models, i.e., both the initial period and the long-term usage.