
使用迁移学习
① 大型存储系统中磁盘故障会导致严重数据丢失甚至难以复原数据;② 当前主流方法还有replication和erasure coding等恢复数据技术,但磁盘故障预测技术不仅可以降低丢失数据的⻛险,还可以降低数据恢复成本;③ 由于缺乏足够少数磁盘的训练数据,需要大量训练数据的传统ML方法容易发生过拟合,无法展示出优秀的预测效果;
使用的方法
- 使用迁移学习从可用的多数磁盘数据集中预测少数磁盘的故障
- 使用一种基于KLD值的方法来选择合适的多数磁盘模型
主要内容
少数磁盘的定义:1500为分水岭(?)
为什么使用迁移学习
每个制造商的不同磁盘模型的故障模式十分相似
⇒ 应⽤迁移学习来进⾏跨模型磁盘故障预测
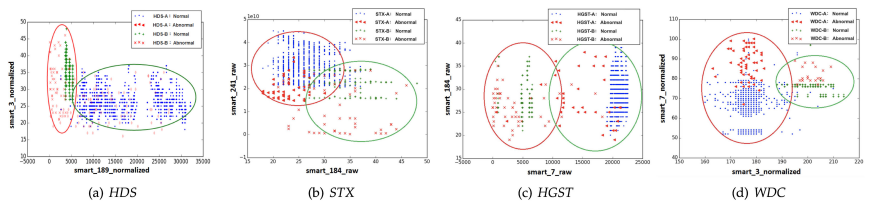
同⼀制造商的不同磁盘型号表现出不同的SMART值分布
⇒ 基于传统 ML 算法使⽤⼀种磁盘模型的训练数据建⽴的预测模型不适⽤于其他即使来⾃同⼀制造商的不同模型
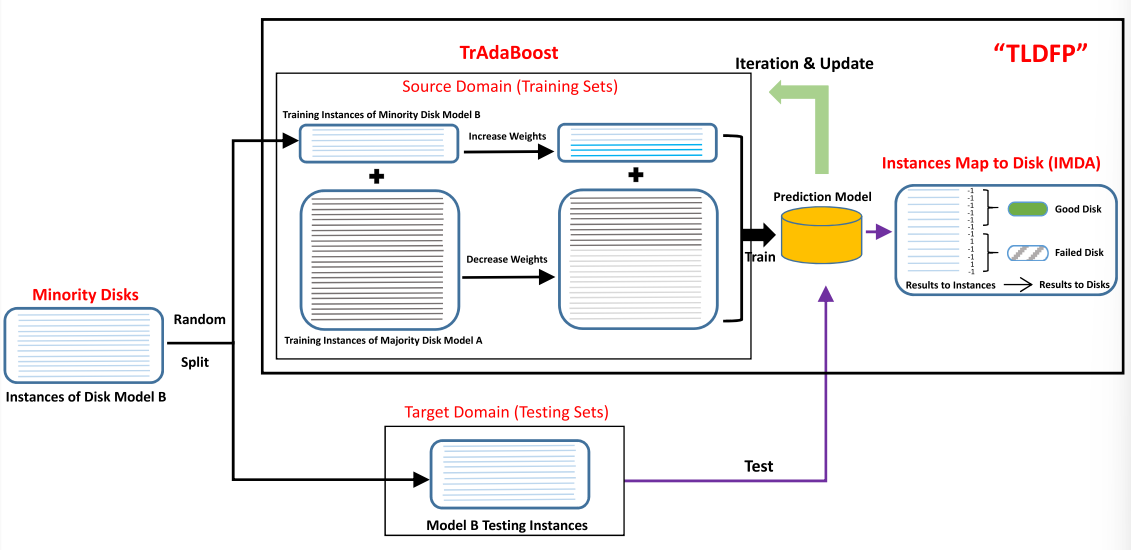
如何使用迁移学习(算法细节)
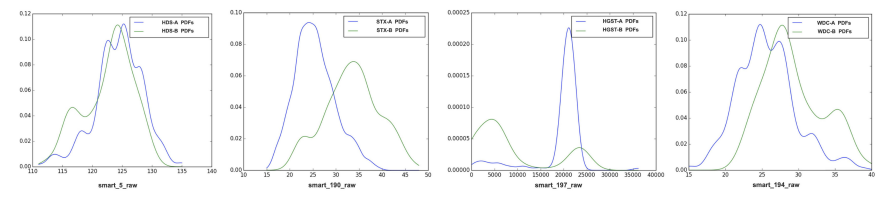
何时使用迁移学习(KLD的使用)
衡量⼀个概率分布与另⼀个预期概率分布的分歧程度的指标,表⽰两个随机变量分布之间的差异。
零 KLD 值意味着两个随机分布相同,KLD 值随着两个随机分布之间的差异扩⼤⽽增加。KLD 值越⼤,两个分布之间的差异越⼤,两个分布之间的迁移就越困难。
实验:数据集、对比的算法、优越性
数据集
Backblaze的SMART开源数据集和腾讯数据中⼼的数据集。使用欠采样类,故障:良好 = 1:3,训练集和测试集7:3,交叉验证。
对比的算法
与传统ML算法相比较 ⇒ 3.3
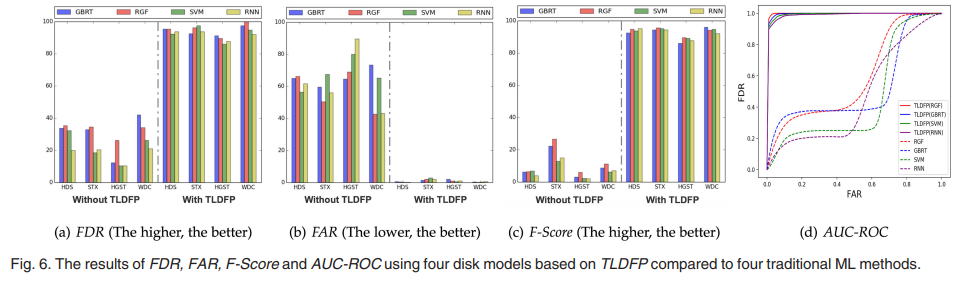
- FDR:四种传统的 ML ⽅法都不能使⽤⼤型异构数据集提供⾼ FDR。⽽TLDFP分别使⽤GBRT、RGF、SVM、RNN算法作为基础学习器均取得了较⾼的FDR。
- FAR:四种传统的 ML ⽅法都不能在少数磁盘上同时提供⾼FDR 和低 FAR。传统 ML ⽅法导致的预测性能差,⽆法减少⽬标域中少数磁盘数据集与源域中多数磁盘数据集之间的分布差异。
- F-Score:TLDFP 的 F-Score 远⾼于其他不同的传统ML⽅法(9 倍)
- AUC-ROC:TLDFP 的 AUC-ROC 曲线都靠近左上⻆,四种传统的ML⽅法获得了较低的 AUC 值
与其他同样使用迁移学习算法的模型作对比(SSDB, TLBN)
虽然SSDB匹配了源域和⽬标域的分布,但它只是对源域中的观察进⾏了排序,⽽TLDFP对每个观察进⾏了更有效的权重调整。
TLBN:多源域迁移学习,TLDFP:单源域迁移学习。
分析KLD的值:TLDFP会选择源域中KLD值最小的,即差异最小的
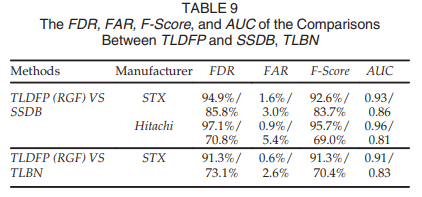
优越性
对于相同的数据集,TLDFP可以有效地解决少数磁盘故障预测问题,其预测性能⽐传统ML⽅法和其他两种迁移学习⽅法要好得多。
TLDFP不仅提供⾼ FDR、F-Score 和AUC,同时还显⽰出相当低的 FAR。
⇒ TLDFP 算法能够利⽤少量标记的⽬标磁盘数据建⽴源和⽬标磁盘模型之间的联系,减少了源域和⽬标域之间的数据分布差异,使模型得到良好的训练。
其他笔记
SMART
自我监控、分析和报告,属性包含着磁盘逐渐退化和可能却显得信息。若属性的值超过相应的预定义阈值则磁盘将自动报警。
缺点:FDR:3-10%,FAR:0.1% ⇒ 不够理想,故障检测率太低,太保守
SMART属性的组成
- ID
- normalized value (1~253)
- raw value:原始值
- threshold:磁盘发出故障警报的阈值
- worst:给定属性的最低或最差值
⼤规模SMART数据采集框架:有效解决海量存储和检索难的问题
TrAdaBoost